Notes on the "RAG Paper"
July 16, 2025 · Learning AIThese are my notes for the paper 'Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks (2005.11401v4)' published in 2020.
My intention with these notes is not to go too deep into the mathematics involved. Where required, some mathematical information is included. The assumption is also that you are familiar with high-school level mathematics. Maybe you don't remember all of it, but if you hear something and you can recognize the concept, it should be enough to understand these largely. I also assume that you understand how a model is trained at a very basic level.
I’d also recommend reading this alongside the original paper. It helps to refer to the figure and notations directly as you go.
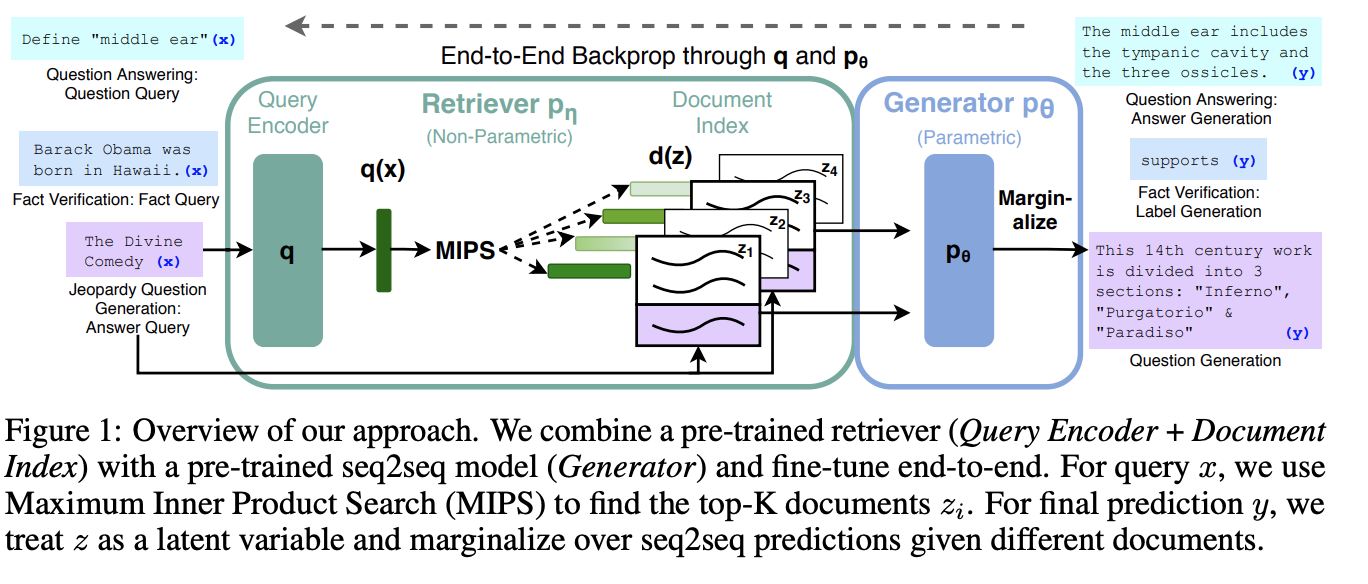
Figure from the paper illustrating the approach
Terminology
- Upstream Tasks: Tasks which affect the model -> tasks which help the model make sense of the unlabelled data. (not that important for this paper)
- Downstream Tasks mean the specific language tasks we want to solve after pretraining a language, like QnA, sentiment analysis, summarization etc.
- Pretraining refers to the initial training phase where model learns general language patterns by processing large amount of unlabelled data.
- Parametric memory: Trained part of the model. Parameters of the model are fixed after training phase. This can't be changed without training.
- Non-parametric memory: Things stored outside the model, fetched via a 'retriever'.
- seq2seq model: sequence-to-sequence model. maps one sequence to another for tasks of taking one sequence as input and emitting other as output.
- Extractive downstream tasks: Extracting information from documents.
- Differentiable access mechanism: Mechanism to retrieve the relevant documents.
Overview
- Pretrained models with just parameterized knowledge base are fixed. Its difficult to revise their memory.
- You can't see where the predictions are coming from -> prone to hallucinations
- Solution: Hybrid models combining parameterized and non-parameterised memory
- knowledge can be revised and expanded
- accessed knowledge can also be inspected
- REALM and ORQA are two such models but they only extract the information.
- Components
- Parametric memory: pretrained seq2seq transformer (BART)
- Non-parametric memory: Dense vector index of Wikipedia
- Retriever: Dense Passage Retriever (DPR)
- Top-K approximation used for the document retrieval
- Previous models with non-parametric memory for were trained for specific tasks. This paper just uses pre-trained memory components.
- These are tasks which even humans can't perform without access to an external knowledge source.
- These RAG models achieve remarkable results on multiple benchmarks also outperforming other approaches in one.
- Models generate more factual, specific and diverse responses than BART baseline.
- In a fact verification benchmark, model performs within 4.3% of other state of the art models.
- Changing the memory is also demonstrated.
Methods
Mathematical Sidenote
The notation pₖ(y|x) is used to represent conditional probability distribution of y, for a given x. k represents the parameters of the distribution.
Latent variables are unknown variables which can't be observed directly, but they affect the outcome.
Marginalization is way to calculate the total probability of something by considering all possible values of the unkown (latent) variables. Since latent variables are unobserved, we can't pick one, so all of them are included.
Components and Notation
- x : input sequence
- y : output/target sequence
- z : text documents
Based on above, the components are denoted as:
- Retriever
- Retriever is supposed to fetch the documents z, given the input sequence x.
- It does that by determining probability for different documents, based on x.
- The distribution is parameterized by η. These are the parameters within the model which are tuned as part of the training.
- Generator
- Generator is supposed to generate tokens based on the input sequence x, documents z and the previous tokens.
- This again depends on the probability distribution of the tokens.
- θ refers to the parameters of the model, tuned via training.
- Generators have been using this technique of predicting the next token for a while. This wasn't the breakthrough of 'Attention is all you need'.
The documents are treated as latent variables.
'Marginalizing the document to get the generated sequence' just means calculating the probability for output sequence using the identified relevant documents, each weighted by relevance.
Models
As discussed before, two different ways are used to generate the output sequence:
- RAG-Sequence Model
- Uses same retrieved document to generate the complete sequence.
- Retrieved document treated as a single latent variable
- The probability of getting output for a given input is denoted by:
- The output depends on the token coming before each, so if we write in terms of each $i$:
- Since the document z is going to be common for all tokens, p(z|x) doesn't need to be part of the term for each i. Its kept separate from the product.
- RAG-Token Model
- Draw from a different latent documents for each target token.
- The probability of output for a given input is denoted as:
- For each token, the document is retrieved. So this time $p(z|x)$ is part of the product term.
The summation in both cases is performed for the top-K documents retrieved for the input.
For sequence classification case, where target sequence of length one is considered, both models are equivalent.
Components
Both RAG models, RAG-Sequence and RAG-Token use the same retriever (DPR) and generator (BART). Its the manner of their usage, which differs.
Retriever - DPR
- The documents are first encoded by BERT (base) document encoder. This converts the documents into vector embeddings. This is denoted as d(z).
- The query (input) is also encoded by the same. This is denoted as q(z).
- DPR retrieves the top-k documents with highest probabilty using MIPS
- MIPS (Maxiumum Inner Product Search) is a similarity search method. It retrieves the documents whose embeddings have the highest dot (inner) product with a query embedding. This is represented in the paper as: pη(z∣x)∝exp(d(z)⊤q(x))
Generator - BART
- BART (large) is used here. Its a seq2seq transformer with 400M parameters
- Any encoder-decoder could have been used for this purpose
- The model selection depends on what's state-of-the-art at the time and also what's more accessible. Since this research originated at Facebook (now, Meta), using BERT made sense since it was already state-of-the-art at that time, and since it was a model from facebook, they would have more understanding and more control over tweaking it.
- When predicting the next token, it is based on what has been predicted till now. To do this, the retrieved content and input is concatenated.
- This model has previously also achieved state-of-the-art results on various generation tasks and outperformed similar models at the time.
- BART generators internal parameters (parametric memory) is denoted as θ.
Training
This is quite interesting. So the mechanism requires the documents to be encoded via a document encoder. But if you train the document encoder again, the previous embeddings become meaningless, and you'd have to perform the encoding again.
This was attempted by another model REALM during pre-training and obviously turned out to be quite costly. Instead, here the document encoder is kept fixed along with the encoded index.
Only the query encoder and the generator are fine tuned.
Now the purpose of any learning is to minimize a loss function. The minimization of the 'negative marginal log-likelihood' is just a standard for seq2seq models. Basically, you want to tune the parameters in such a way that you maximize the probability of the correct answer getting picked. You can also turn it around and say, you want to minimize the negative probability of the correct answer getting picked.
Training is done via gradient descent and most optimizers (used for training) support this downhill roll, rather than an uphill climb, which is why its flipped. You keep moving downhill, until you're in the valley's deepest point (the minimum).
Logarithmic just makes the gradient more stable and turns product into sum. If you keep multiplying the probabilities for each pair, it could limit zero.
Decoding
Decoding process of both models is different.
RAG-Token
The per-token nature of generation was established as a standard up until that time. So, RAG-Token model simply used that. It does that using beam search.
Beam search predicts possibility of next-token from its vocabulary, takes the top-k tokens, predicts the next possible token for each of those $k$ tokens, and continues to do so until end-of-sequence.
In RAG-Token, the vocabulary is the entire document index. So this can be used directly.
RAG-Sequence
In RAG-sequence though, the vocabulary can't be the entire document index. It needs to pick a single document which is most relevant. Thus, beam search is performed for each document. This results in a set of hypotheses Y. These are the set of output sequences from each document.
Thorough decoding: The decoder is re-run for each hypotheses y, against each document z except for the one it was generated from.
Fast decoding: Additional pass is skipped for longer output sequences for efficiency. In this case, its assumed that the probability for y, against each document it was not generated from is 0. That is:
These give the probability of how likely y is, if model had access to just z. Each such term is multiplied with the p(z|x), which is the probability of z being the right document for the input x. Combining both (summation) gives us the marginal probability of y emerging from x.
After this, the hypotheses with the highest probability is selected as the output sequence.
The experiments, results, model comparison etc will be covered in a follow-up.